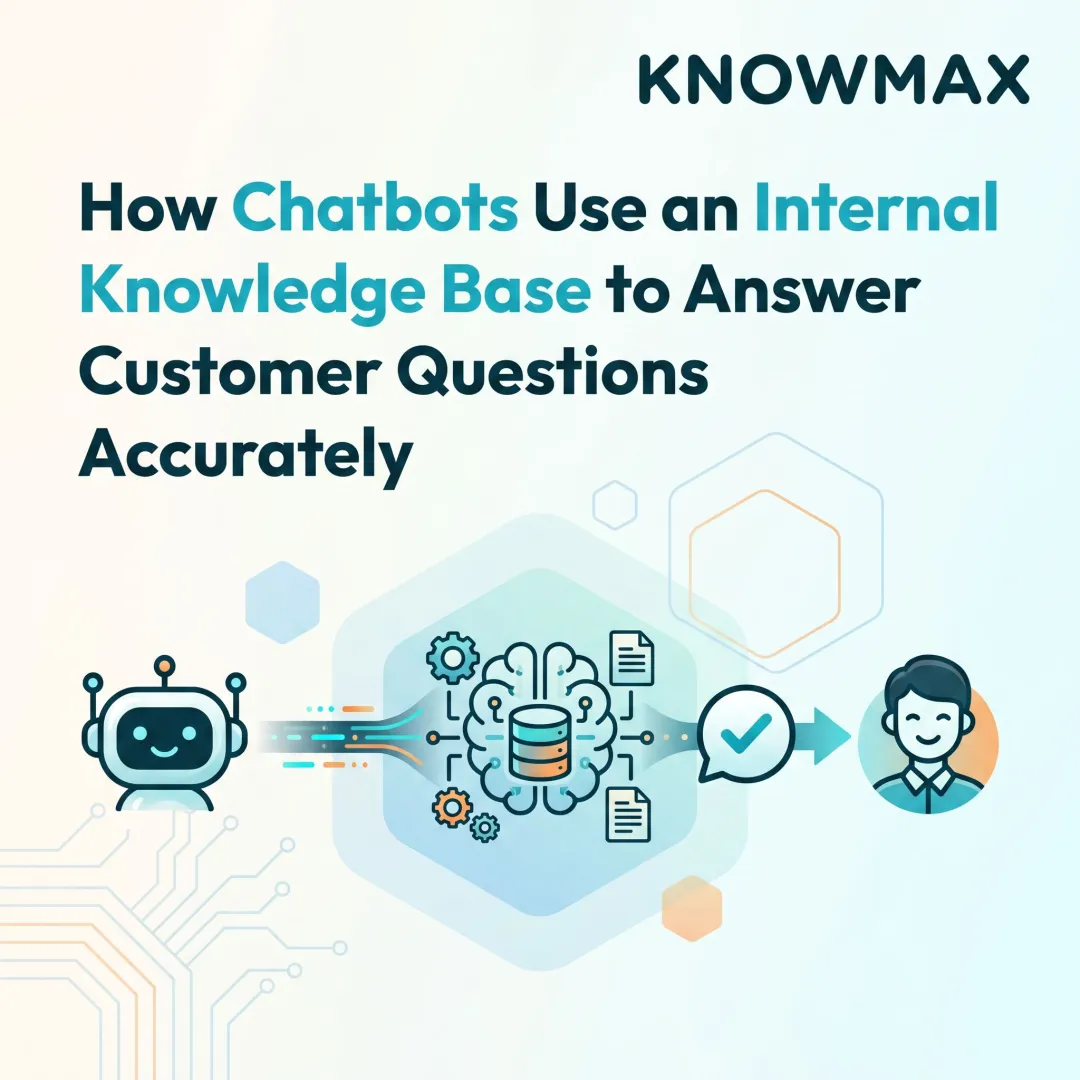
Introduction
Enterprise AI agents are only as accurate as the knowledge grounding them — and most deployments are failing quietly. Enterprise chatbot deployments report approximately 18% hallucination rates in live interactions, with hallucinated citations appearing in over 30% of chatbot-generated responses. The cost of these errors is steep: 39% of AI-powered customer service bots were pulled back or reworked in 2024 due to hallucination-related failures.
The gap between what foundation models know and what they need to know about your specific business is massive. Generic LLMs have training cutoffs, no access to your private policies or product specs, and fill information gaps with plausible-sounding but fabricated answers. The result: inconsistent responses to identical queries, eroded customer trust, and operational risk at scale.
That operational risk has a specific solution — but most organizations approach it wrong. "Training" an AI agent on enterprise knowledge doesn't mean retraining the model from scratch. It means connecting the agent to your knowledge base using Retrieval-Augmented Generation (RAG), where accuracy lives or dies based on how that knowledge is structured, indexed, and retrieved. This article covers the exact steps to connect AI agents to enterprise knowledge bases, the parameters that determine accuracy, and the failure points that trigger hallucinations.
TL;DR
- Training AI agents means connecting them to your knowledge base via RAG, not retraining the model
- Knowledge base quality, structure, and freshness directly determine agent accuracy
- Accuracy depends on five steps: auditing content, chunking intelligently, embedding correctly, building reliable retrieval pipelines, and testing before deployment
- Most accuracy failures trace back to poor document quality, inconsistent chunking, or the absence of any evaluation framework
- Treat knowledge base maintenance as ongoing work — stale content degrades agent accuracy just as fast as bad setup
Why Enterprise AI Agents Lose Accuracy Without a Structured Knowledge Base
Foundation models face a fundamental limitation in enterprise contexts: they have training cutoffs, no access to private data, and fill information gaps with fabricated answers. RAG reduces hallucination rates by 30% to 70% by grounding responses in retrieved enterprise content rather than relying on the model's parametric memory alone.
The data fragmentation problem makes this worse. 80% of companies cite data limitations as the primary roadblock to scaling agentic AI, yet fewer than 10% have scaled AI agents to deliver tangible value. Enterprise knowledge lives scattered across:
- CRM records and email threads
- Internal wikis and SharePoint folders
- PDFs, SOPs, and policy documents
When context is fragmented across these sources with no unified structure, AI agents guess — and they guess inconsistently.
The core issue isn't the model — it's the information architecture. An AI agent backed by a centralized, well-maintained knowledge base behaves reliably. The same model without one does not.
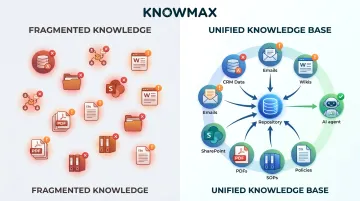
This is where structured knowledge management becomes the prerequisite. Platforms like Knowmax provide AI-assisted authoring, content governance, and tagging workflows that ensure enterprise content is clean and consistently structured before it ever reaches the AI pipeline.
How to Train AI Agents on Your Enterprise Knowledge Base
Step 1: Audit and Prepare Your Knowledge Content
The foundation of accurate AI agents is clean, verified, and well-structured content. An audit means practically:
- Identifying outdated articles and removing conflicting information
- Merging duplicate entries
- Ensuring each document covers a single topic clearly
AI cannot distinguish between accurate and inaccurate information — it treats all ingested content as equally true. A single outdated policy document causes the AI agent to confidently deliver wrong answers at scale. Getting the content right before ingestion is the only way to prevent errors from compounding at scale.
Knowmax supports this with structured content authoring frameworks, maker-checker approval workflows, and content versioning — so only verified, consistently formatted articles enter the knowledge base.
Step 2: Chunk Documents Intelligently
Chunking is the process of breaking documents into smaller retrievable pieces. The strategy used directly impacts retrieval quality. Key approaches include:
- Fixed-size chunking: Consistent token windows (e.g., 256, 512, or 1,024 tokens)
- Semantic chunking: Split at topic shifts or paragraph boundaries
- Recursive splitting: Respect document structure (headings, sections)
NVIDIA benchmarks show page-level chunking achieves highest average accuracy (0.648) with lowest variance. For factoid queries, 256–512 tokens performs well; for complex analytical queries, 512–1,024 tokens or page-level chunking is recommended.
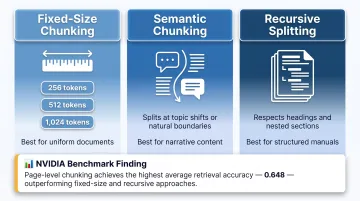
Important: Arbitrary splitting — cutting documents mid-sentence or mid-thought — destroys context and causes the AI to retrieve incomplete or misleading information. Always maintain semantic integrity within each chunk.
Step 3: Generate Embeddings and Build a Vector Index
After chunking, each piece of content is converted into a vector embedding — a numerical representation that captures its meaning, not just its keywords. This enables the AI to find semantically related content even when the user's phrasing doesn't match the document's exact wording.
Two deployment paths are common here:
- Use a hosted embedding model (via API) for ease of setup
- Deploy a self-hosted open-source model for privacy-sensitive environments
- Pair either option with a vector database for fast similarity search
Step 4: Build and Tune the Retrieval Pipeline
The retrieval layer sits between the user query and the language model. Hybrid retrieval — combining vector similarity search with keyword matching — outperforms pure vector search by 18.5% in Mean Reciprocal Rank, especially for queries requiring exact terms, section numbers, or product codes.
Worth noting: untuned hybrid retrieval scored MRR 0.390 — actually lower than pure dense search (0.410). Parameter tuning is mandatory, not optional.
Key retrieval parameters to configure:
- Number of chunks returned per query: Typically 3–5 for standard queries
- Similarity threshold: Minimum relevance score for inclusion
- Reranking: Use a second model to reorder results by relevance before passing to the LLM
A proven approach: retrieve a broad candidate set of 30–50 chunks, then apply a cross-encoder reranker to select the top 5–10 most relevant chunks for the LLM.
Step 5: Test, Evaluate, and Refine Before Deployment
Evaluation before deployment catches failures that surface calls can't. Build a test set of 20–50 representative queries with known correct answers, then track:
- Context precision: Are the retrieved chunks relevant?
- Context recall: Was all needed information retrieved?
- Faithfulness: Does the response stay within the retrieved context?
- Answer relevance: Does the response actually address the question?
A system with acceptable average faithfulness of 0.82 masked individual component scores as low as 0.4. Aggregate metrics hide critical failures — per-query scoring is essential.

Manual spot-checking is insufficient at enterprise scale. Automated evaluation pipelines should flag regressions whenever the knowledge base is updated or retrieval parameters are changed.
What You Need Before Training AI Agents on Enterprise Data
Skipping preparation is the most common reason AI agents underperform after deployment. Before any training pipeline runs, three categories need to be in order: your knowledge base, your compliance posture, and your technical infrastructure.
Knowledge Base Readiness
The knowledge base must be centralized, deduplicated, and consistently structured, with access controls enforced at the content level, before AI training begins. Partial, siloed, or permission-misaligned content leads directly to inaccurate or inappropriate AI responses.
Knowmax's content governance capabilities address this through:
- Authorization workflows ensuring only approved content is published
- Scheduling and archiving to maintain relevance
- Audit-ready content categorization and tagging taxonomies
- Metadata fields (document category, department, date, access level) enabling metadata-driven filtering
With governance in place, the knowledge base becomes a reliable source the AI can draw from — not a liability it amplifies.
Compliance and Security Readiness
Connecting AI to internal knowledge raises data governance requirements:
- Role-based access control (RBAC) using OAuth 2.0 identity injection, tying agent actions directly to user permissions
- Data encryption at rest and in transit, with VPC-native deployment for data residency requirements
- PII redaction at the gateway level, before data reaches the AI model
- Immutable audit logs satisfying NIST AI RMF, ISO 42001, and EU AI Act requirements
Knowmax holds SOC 2, ISO 27001, GDPR, and HIPAA certifications — meaning these controls ship with the platform rather than requiring custom security engineering on your end.
Infrastructure and Integration Requirements
The technical stack needed includes:
- Embedding model (hosted API or self-hosted)
- Vector database for similarity search
- LLM (via API or private deployment)
- Orchestration layer connecting retrieval to generation
Knowmax integrates with leading CRM, CCaaS, and telephony platforms (Salesforce, Zendesk, Genesys, Freshworks, Talkdesk, Exotel) through pre-built APIs and native connectors. This feeds real-time knowledge into AI agent pipelines during live interactions.
With all three prerequisites in place, the actual training process has a solid foundation to build on — which is where most of the accuracy work happens.
Key Parameters That Affect AI Agent Accuracy
Once the pipeline is live, accuracy depends on how well you control specific technical variables. These require ongoing tuning based on real-world query patterns.
Chunk Size and Overlap
Chunk sizing is the most common root cause of retrieval failures — and the easiest to get wrong. Too-small chunks lose context; too-large chunks introduce noise. Overlap between consecutive chunks (typically 10–20%) ensures that information split across a boundary stays retrievable from either side.
NVIDIA tested 10%, 15%, and 20% overlap on FinanceBench with 1,024-token chunks and found 15% to perform best. When sizing is off, the AI retrieves content adjacent to the answer — but not the answer itself.
Retrieval Depth (Number of Chunks Returned)
How many chunks you return to the LLM matters as much as which chunks you retrieve. Too few risks missing critical context; too many floods the model with noise, degrading response quality and increasing cost.
Practical guidelines by query type:
- Standard support queries: 3–5 chunks covers most scenarios
- Complex multi-step queries: Up to 10 chunks — but pair with a reranker to filter irrelevant content
- Long context windows: Watch for the "lost in the middle" effect, where LLMs struggle to extract information buried in the middle of a large context block
Metadata Richness and Filtering
Metadata — document title, category, date, department, access level — lets the retrieval system pre-filter before semantic search runs, improving retrieval precision before the LLM ever sees a result.
Without it, a 2019 policy document ranks alongside a 2025 update. A well-tagged knowledge base ensures the AI agent surfaces current, contextually appropriate content. Knowmax supports metadata fields including document categories, departments, channels, and topic tags, with access control applied at the content level.

Prompt Design for the Language Model
Even with perfect retrieval, a weak prompt can cause the LLM to generate answers beyond what the retrieved chunks actually say. The prompt must explicitly instruct the model to answer only from provided content, cite sources, and acknowledge when information is insufficient.
Prompt-based mitigation reduces hallucinations by approximately 22 percentage points, according to a Nature study. Structured strategies — Thread of Thought, Chain of Note, and Chain of Verification — each show consistent gains. Think of prompt design as the final accuracy guardrail: explicit "stay within context" instructions measurably cut hallucination rates compared to generic prompts.
Common Mistakes That Cause Accuracy Loss When Training AI Agents
Skipping Knowledge Audits Before Indexing: Organizations frequently index their entire document repository without reviewing it first. Conflicting information, outdated procedures, and duplicate articles are treated as equally valid truth by the AI — causing inconsistent and sometimes dangerous responses. Better retrieval technology cannot fix accuracy loss that originates in poor source data.
Uniform Chunking Across All Document Types: FAQs, technical manuals, policy documents, and troubleshooting guides have very different structures and should not be chunked identically. Applying fixed-size chunking universally across a diverse knowledge base is one of the most predictable causes of poor retrieval precision.
No Post-Deployment Evaluation Framework: Many teams deploy AI agents, declare training done, and only discover accuracy problems through user complaints. Without an automated evaluation pipeline tracking precision, recall, and faithfulness metrics continuously, accuracy degrades silently. Outdated information accounts for 18% of hallucinations in enterprise use cases — and most teams never see it coming.
How to Keep Your AI Agent Accurate as Your Knowledge Base Evolves
Training an AI agent is not a one-time event — it is an ongoing operational process. Knowledge bases change constantly: policies are updated, products are launched, procedures are revised. Every change that isn't reflected in the indexed knowledge base is a potential accuracy gap.
Establish a governance cadence for content review and reindexing — triggered by document updates or scheduled quarterly audits. Knowmax's platform includes analytics that surface which queries agents or self-service users failed to resolve, feeding directly into knowledge gap identification and content update workflows.
AI-assisted content maintenance reduces the burden of keeping knowledge current. Knowmax's AI author tools support content rephrasing, summarization, and auto-translation across 25+ languages — enabling knowledge managers to keep enterprise content fresh and accurate, particularly for global contact center environments.
The specific capabilities that support this include:
- Rephrasing and summarization to align existing content with AI retrieval patterns
- Auto-translation across 25+ languages for multilingual support operations
- Scheduled reindexing triggers tied to document update events or quarterly audits
- Analytics-driven gap detection that surfaces failed or escalated queries for review
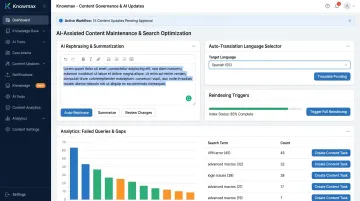
Monitoring which queries the AI agent fails to answer, escalates, or answers inconsistently reveals specific knowledge gaps. Those failure patterns should directly drive knowledge base updates — creating a continuous improvement cycle that raises accuracy over time rather than allowing it to erode.
Conclusion
AI agent accuracy on enterprise knowledge isn't determined by the model — it's determined by the quality, structure, and governance of the knowledge base it's trained on. The practices covered in this article are what separate reliable, enterprise-grade AI agents from ones that hallucinate and erode user trust.
The organizations seeing the strongest results treated knowledge management as the primary investment. Before connecting any model, they ensured content was clean, current, and properly indexed. The results bear this out:
- Vodafone achieved measurable reductions in Average Handle Time
- A leading telecom company saw a 21% improvement in First Call Resolution by grounding AI agents in structured knowledge
- Across industries, structured knowledge bases consistently outperform unstructured ones on accuracy and containment rates
Get the knowledge foundation right, and accuracy follows. Skip it, and no amount of model tuning will compensate.
Frequently Asked Questions
How to build a knowledge base for AI agent?
Building a knowledge base for an AI agent involves centralizing and auditing enterprise content, chunking it into semantically coherent pieces (typically 256–512 tokens with 10–20% overlap), generating vector embeddings, and storing them in a searchable index. This lets the AI retrieve relevant context at query time rather than guessing from training data alone.
Can AI agents be integrated with existing enterprise systems?
Yes, AI agents integrate with CRMs, ticketing systems, ERPs, and communication platforms through APIs and connectors. Retrieved knowledge from these systems is surfaced to the agent via RAG pipelines, enabling it to act on live enterprise data from platforms like Salesforce, Zendesk, Genesys, and Freshworks.
What is the difference between RAG and fine-tuning for enterprise AI agents?
RAG connects an AI agent to a live knowledge base at query time: it's fast, updatable, and cost-effective. Fine-tuning modifies the model's weights to internalize patterns — a process that's expensive, slow to update, and unnecessary for most enterprise accuracy use cases where RAG is sufficient.
How do you prevent AI agents from hallucinating on enterprise data?
Hallucinations are prevented by grounding the AI strictly in retrieved enterprise content and designing prompts that explicitly restrict the model to that context. Queries where retrieved chunks fall below a confidence threshold should be flagged rather than allowing the model to generate unsupported answers.
How often should you update your knowledge base for AI agents?
Reindexing should be triggered by content changes (policy updates, new products, procedure revisions) rather than on a fixed calendar. Schedule a quarterly audit to catch drift, remove outdated content, and identify knowledge gaps surfaced by agent failure patterns.
What content formats work best for training AI agents on enterprise knowledge?
Well-structured text — clearly written articles, SOPs, FAQs, and policy documents with descriptive headings and consistent formatting — performs best. PDFs, Word documents, and web content can all be ingested, but content quality matters more than format; ambiguous or jargon-heavy writing degrades retrieval accuracy.