
Introduction
AI-powered support tools are only as smart as the knowledge base behind them. When a contact center agent or chatbot surfaces a wrong answer, the culprit is almost always stale, conflicting, or poorly structured KB content, not the AI itself.
According to the Calabrio 2025 State of the Contact Center report, 98% of contact centers have integrated AI, yet 61% report conversations have become more difficult. Meanwhile, Salesforce data reveals that 62% of agents say help pages aren't up-to-date, and 59% find instructions too complicated.
What follows covers the governance models, update workflows, and agent feedback loops that keep your knowledge base accurate as your products, policies, and processes change — so your AI stops confidently repeating yesterday's answers.
TLDR
- AI accuracy depends entirely on KB quality—outdated or disorganised content directly causes hallucinations, conflicting answers, and lost customer trust
- A single source of truth and a well-structured content taxonomy are foundational before connecting any KB to AI
- Syncing requires defined ownership, change-triggered update workflows, and ongoing content audits — not a one-time configuration
- AI can help maintain itself by flagging low-confidence answers, surfacing stale articles, and identifying content gaps
- Track sync health through metrics like AI resolution rate, escalation patterns, and article freshness percentage
Why a Dirty Knowledge Base Is Your AI's Biggest Liability
The "garbage in, garbage out" principle applies ruthlessly to AI-powered knowledge systems. When AI retrieves information, it cannot independently judge whether a policy has changed or whether two conflicting articles exist—it will confidently surface whichever content it deems most relevant, even if that content is outdated.
Three Critical KB Data Problems
Duplicate or conflicting articles covering the same topic with different information create the most dangerous failure mode. An AI system presented with a "Refund Policy" article from 2023 and another from 2025 will select one based on relevance scoring, not recency. The customer receives confident misinformation.
Stale content reflecting discontinued products, old pricing, or expired policies builds up unnoticed. HDI/MetricNet benchmark data (cited by HappySupport, 2026) places B2B support ticket resolution costs at USD $15–22 per incident — a chatbot with 30% accuracy issues across 500 monthly queries adds roughly USD $2,300–$3,300 in avoidable support costs every month.
Orphaned content—articles that exist but are no longer linked or indexed—creates invisible inconsistencies. These articles still appear in search results and AI training corpuses, but no human curator knows they exist or remembers to update them.

Legal and Operational Consequences
The Air Canada chatbot incident established precedent: civil resolution tribunals now rule that companies are legally liable for misinformation provided by chatbots. A tribunal rejected the defence that a chatbot is a "separate legal entity," according to CMSWire (2025). This extends poor KB quality from operational losses to legal and regulatory risk.
The Userlike Survey (2023) found that 58% of customers have reported negative experiences with chatbots. That dissatisfaction doesn't reflect AI model limitations—it reflects the quality of the knowledge feeding those models.
The Compounding Problem
Legal exposure is the downstream result of a more fundamental gap: AI systems have no mechanism to detect when the knowledge they draw from has gone stale. Unlike a human agent who notices when a policy changes, an AI will keep surfacing outdated content until a human intervenes.
GitLab DevSecOps Survey data (cited by HappySupport) reveals that 65% of software teams ship new code or updates at least weekly. For those teams, the useful life of a KB article is measured in weeks, not months. When documentation reviews happen monthly but code ships weekly, each review cycle begins with 3–4 releases of undocumented changes already in production.
That gap doesn't stay invisible. It surfaces as customer complaints, agent escalations, and the kind of legal liability the Air Canada ruling made concrete.
How to Structure Knowledge Base Content for AI Readiness
Establish a Single Source of Truth
Multiple repositories create the exact contradictions AI cannot resolve. A SharePoint folder, a ticketing tool's internal notes, and a standalone KB each claiming authority over the same policy will cause AI to surface conflicting answers.
Gartner's 2025 guidance on structuring content for AI emphasises that all content the AI will draw from must live in one centralised, authoritative system. KMWorld 2024 data shows that 54% of organisations use more than 5 different platforms to document and share information—this fragmentation makes AI retrieval fundamentally unreliable.
Knowmax addresses this through a unified cloud-based knowledge platform where content is authored once and automatically propagated across all channels: voice, chat, email, social media, websites, mobile apps, and chatbots. This eliminates the inconsistencies that come from maintaining separate knowledge bases per channel.
Design a MECE Content Ontology
Categories at every hierarchy level should be mutually exclusive (no overlap) and collectively exhaustive (covering every topic a customer might ask).
Good example: A "Fees" category containing sub-articles like "Late Payment Fees," "Equipment Damage Fees," and "Cancellation Fees" is MECE.
Bad example: A single "General Fees" article is not MECE—it forces a single article to cover multiple distinct topics, degrading AI retrieval precision.
When AI retrieves at the article level, a single article covering five topics may pull an irrelevant section in response to a specific query.
Write for AI Parsing
AI models use document structure to understand hierarchy, context, and relationships between topics. Use:
- HTML headers (H1/H2/H3) to establish content hierarchy
- Numbered lists for sequential processes
- Bullet points for options and features
- FAQ-style Q&A pairs for common questions
Knowmax supports structured article formatting through its WYSIWYG editor, allowing authors to create properly hierarchical content with headings, lists, and embedded Q&A pairs. Avoid relying on bold text or rich formatting alone as a substitute for proper semantic structure.
Keep One Topic Per Article
Each article should answer one question fully, without requiring the reader or the AI to reference another document. AI retrieves at the article level—if a single article covers billing, refunds, and account closures, the AI may pull the wrong section in response to a specific query about refunds.
Use Precise, Standardised Terminology
If the KB calls a product feature a "bundle" in some articles and a "package" in others, the AI cannot reliably group those concepts. Maintain a controlled vocabulary—a glossary of approved terms that all KB authors use consistently.
Knowmax's AI author features help standardise existing content at scale:
- Rewrite inconsistent phrasing across articles without manual review
- Generate instant summaries to standardise how content is previewed
- Translate content into 25+ languages while preserving terminology consistency
This reduces the risk of terminology drift as your KB scales.
A Note on Visuals and Unstructured Content
Most AI systems process plain text best. Charts, images, and complex tables should always be accompanied by a written description.
For visuals containing critical information—such as a troubleshooting flowchart—the text alternative should be a complete prose or structured-list version of the same content. Forrester's Guide to Retrieval-Augmented Generation (November 2024) stresses that businesses must "prepare their data for AI readiness, ensuring it's clean, structured, and ethically sourced."
Knowmax gives authors the tools to make visual content AI-parseable without extra effort:
- Upload images in bulk and add instructional text at each step
- Convert complex SOPs into interactive decision trees with guided workflows
- Auto-generate video walkthroughs from visual guides, paired with text-based alternatives
This means visual content stays useful to both human readers and AI retrieval systems.
Best Practices for Syncing Your KB with AI: Workflows and Governance
What "Syncing" Actually Means
Syncing is not connecting a KB platform to an AI tool once. It's the ongoing process of ensuring that every time a product changes, a policy updates, or a new service launches, the KB reflects that change before the AI surfaces answers about it.
Two modes exist:
- Reactive syncing: Updating KB after a problem is detected
- Proactive syncing: Updating KB ahead of product and policy changes
Only proactive syncing prevents AI from delivering wrong answers.

Establish Ownership and Accountability
A KB without a named owner degrades rapidly. The role of a Knowledge Manager or KB Owner includes:
- Auditing content regularly
- Coordinating updates with product and policy teams
- Maintaining the content calendar
- Tracking review cycles
Larger organisations may need a tiered model: subject matter experts own specific content domains, while a central Knowledge Manager holds overall governance authority. Knowmax supports this through role-based access, administrator assignment, and an authorisation workflow that requires approval before any content goes live.
That governance structure matters more as AI takes a larger role. APQC's 2025 state-of-the-industry research found that 44% of KM experts now rank generative AI as the most important technology for knowledge management — which means the KB feeding that AI needs equally rigorous oversight.
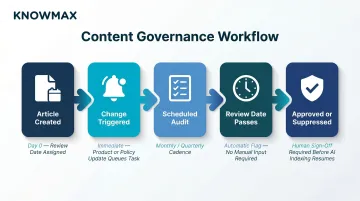
Build Change-Triggered Update Workflows
Every product launch, policy revision, or process change should automatically trigger a KB review task. Implement this by integrating the KB platform with the product roadmap or change management system.
When a policy is updated in the source system, a KB review task is created automatically. Knowmax integrates with the platforms where agents already work, including:
- Salesforce, Zendesk, and Freshdesk
- Genesys, Talkdesk, and Exotel
- SAP and other enterprise systems
Open APIs extend this further, supporting custom integrations for more complex change-triggered workflows.
Implement a Content Review Cadence
Beyond change-triggered reviews, establish a scheduled audit cycle:
- Monthly for high-traffic articles
- Quarterly for lower-traffic content
- Immediate for compliance-sensitive topics
Each audit cycle should target content that is most likely to mislead. Look for:
- Articles with outdated dates
- References to discontinued products
- Pricing that has changed
- Policies that no longer apply
Use Content Expiry and Review-Date Tagging
Assign every KB article a "review by" date at creation, especially for time-sensitive content like promotional policies, compliance requirements, and product specs.
Knowmax supports content scheduling and archiving, allowing users to set specific start and end dates for content availability. When a review date passes without action, the article is flagged and suppressed from AI indexing until someone approves it — so stale content never reaches an agent or customer without a human sign-off first.
Letting AI Help Maintain Itself: Feedback Loops and Auto-Flagging
The Bi-Directional Feedback Loop
The KB feeds the AI, but the AI's interaction data should feed back into KB maintenance. When the AI generates low-confidence answers, fails to resolve a query, or receives a negative user rating, those signals point directly to KB gaps — missing content, ambiguous articles, or topics that simply haven't been written yet.
Operationalising the Loop
Regularly review:
- AI conversation logs
- Escalation patterns
- Low-satisfaction queries
Topics generating frequent follow-up tickets, agent escalations, or thumbs-down ratings should be prioritised for new or revised KB articles.
The Knowledge-Centered Service (KCS) methodology, developed by the Consortium for Service Innovation, is the industry-standard framework for demand-driven knowledge creation. KCS positions knowledge as created "in the context of demand or use" rather than through scheduled authoring cycles. The Consortium explicitly frames KCS as a prerequisite for AI success — agentic and LLM solutions are only as effective as the content they consume.
Organisations adopting KCS report quantified benefits:
- 50–60% improvement in time to resolution
- 30–50% increase in first contact resolution
- Up to 50% case deflection through self-service
Knowmax supports this feedback loop through:
- Thumbs up/down ratings on content
- Unresolved query logging to identify KB gaps
- Escalation pattern reporting analysing conversations with agents and bots
- Micro-segmented analytics tracking time spent on content, most-viewed articles, and feedback trends
These feedback signals are also reshaping team structures. According to eGain (January 2026), 58% of service leaders plan to transition agents into knowledge management specialist roles — dedicated to analysing inquiry patterns and AI performance gaps to drive continuous KB improvements.
Disabling AI Indexing for Unverified or Stale Articles
Rather than waiting for a full audit cycle to fix problematic content, teams can suppress low-quality or flagged articles from AI indexing temporarily. This is a triage measure — the AI won't serve a wrong answer while the correct one is being written.
In Knowmax, suppressing an article from AI indexing takes effect in real time, meaning a flagged article stops surfacing immediately — not at the next scheduled sync. This prevents a window where stale content reaches customers while the corrected version is still in review.
How to Measure Knowledge Base and AI Sync Health
Primary Metric: AI Resolution Rate
AI or automated resolution rate is the clearest indicator of KB quality. When the KB is well-structured and current, the AI resolves more queries without escalation. A declining resolution rate, especially after product changes, often signals that KB content has fallen out of sync.
Key benchmarks from Gartner and ICMI (2024–2025):
- 73% of customers attempt self-service
- Only 14% of issues are fully resolved via self-service alone
- Basic chatbot deflection range: 10–30%
- Advanced AI chatbot deflection range: Up to 92%
The wide range between basic and advanced chatbot deflection underscores that KB quality is the differentiating factor, not the AI model itself.
Supporting Metrics to Track
- Escalation rate — Rising escalations tied to specific topics point directly to stale or missing KB content.
- Article helpfulness scores — Thumbs up/down ratings give direct, low-friction signal on whether content is actually resolving queries.
- Content freshness score — Knowmax tracks this as the percentage of articles reviewed or updated within a defined review window, flagging overdue content automatically.
- Search success rate — Measures how often searches return relevant results, exposing gaps in content coverage or taxonomy structure.

According to ICMI's State of the Contact Center 2024, only 14% of contact centers measure deflection rate and 13% measure self-service accessibility—the two metrics most directly tied to KB-AI sync health. This measurement gap explains why KB quality problems persist undetected.
Build a Simple KB Health Dashboard
A regular report covering three core areas is enough to stay ahead of sync issues:
- Top 10 topics generating AI escalations
- Number of articles past their review date
- Overall resolution rate
Knowmax's built-in analytics surface engagement patterns, most-viewed articles, and feedback trends — giving KB managers the data to act before resolution rates slip.
Tracking these numbers consistently also has a direct cost implication.
Cost Trajectory Warning
Gartner predicts (January 2026) that GenAI cost per resolution will exceed $3 by 2030—higher than many B2C offshore human agents—driven by rising data centre costs and AI vendor price increases. Meanwhile, over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs and inadequate risk controls.
Organizations that invest in KB quality now will achieve better AI accuracy at lower token costs. Those relying solely on AI model improvements will face escalating expenses with diminishing returns.
Frequently Asked Questions
How to make AI answers more accurate?
AI accuracy depends directly on knowledge base quality. Content must be structured with proper HTML headers and lists, non-contradictory across all articles, current with recent product and policy changes, and written with precise terminology so the AI can retrieve and contextualise it correctly.
How do AI systems improve their knowledge base?
AI improves KB quality through feedback loops: analysing which queries went unresolved, which answers received low ratings, and which topics generated escalations. These signals are surfaced to human KB managers for content creation or revision, creating a continuous improvement cycle.
What are the 4 C's of knowledge management?
The 4 C's are Capture, Curate, Connect, and Collaborate. Capture collects important information before it's lost. Curate organises it for easy retrieval. Connect links related ideas to uncover insights. Collaborate shares knowledge so teams work smarter, according to Mem.ai (February 2025).
How often should a knowledge base be updated for AI?
High-traffic or policy-sensitive articles should be reviewed monthly—or immediately when a relevant change occurs—while lower-priority content warrants a quarterly audit. All articles should carry a review-by date, with KB review cycles aligned to your team's deployment cadence.
What is knowledge base data hygiene?
KB data hygiene refers to the ongoing practice of removing duplicate, outdated, and conflicting content from a knowledge base to ensure that any AI system drawing from it receives clean, accurate, and consistent information—eliminating the "garbage in, garbage out" problem.
How do you prevent AI from giving outdated answers?
Assign review dates to all articles and build change-triggered workflows that queue KB updates whenever policies shift. Suppress unverified content from AI indexing in the interim, and monitor escalation patterns to catch content drift before it reaches customers.


