
Introduction
Enterprises racing to deploy AI-powered knowledge bases focus primarily on the benefits: faster answers, reduced Average Handle Time (AHT), improved Customer Satisfaction (CSAT) scores. Vendor marketing and industry coverage reinforce these promises, creating an adoption wave driven by efficiency metrics alone.
Yet a distinct category of risks specific to AI knowledge systems goes largely undiscussed until after deployment. Unlike generic AI concerns around bias or cybersecurity, these risks are slow-burning and structural — eroding answer quality, diminishing agent capability, and draining institutional knowledge before anyone notices.
By the time quality issues surface, they're typically misattributed to agent performance rather than the knowledge system itself.
What follows examines five underexplored risk categories unique to enterprise AI knowledge bases — how each manifests in contact center and CX operations, and what separating a risk-aware deployment from a reactive one actually looks like.
TLDR
- Outdated content gets served with the same confidence as current information, creating compliance exposure
- Semantic search can expose restricted documents to unauthorized users when access controls aren't explicitly architected
- AI-generated content creates accountability gaps—no one owns what the AI writes
- Agents lose critical reasoning skills through over-reliance on AI-served answers, making organizations fragile during system failures
- Knowledge capture stops when teams assume "the AI handles it," accelerating institutional knowledge loss
Why Enterprises Trust AI Knowledge Bases More Than They Should
AI knowledge bases deliver polished, natural-language answers instantly, creating a perception of reliability that traditional keyword search never achieved. 66% of employees who use AI at work have relied on its outputs without verifying accuracy, according to research from the University of Melbourne and KPMG covering 48,000+ respondents across 47 countries. This overtrust creates the foundation for every other risk category.
The confidence problem is structural: unlike database queries that return no results when information is missing, generative AI systems synthesize answers from whatever content is available. Silence is replaced with plausible-sounding fabrication. An agent receiving a confidently delivered but incorrect answer has no visible reason to doubt it — and that's precisely where procurement decisions tend to fall short.
Most enterprise AI knowledge base evaluations prioritize deployment speed, integration capabilities, and cost — not governance. Three critical questions routinely get deferred until after go-live:
- What happens when the system surfaces a wrong answer?
- Who is accountable for the downstream decision made on that answer?
- How does role-based access interact with AI-generated search results?
Organizations that perform regular AI system assessments are over three times more likely to achieve high GenAI value, yet only approximately 20% of companies have mature AI governance. The risks this gap produces — in compliance, accuracy, and accountability — are what the rest of this piece examines.

The Risks Nobody Warned You About
Stale Knowledge Served with Confident Authority
AI knowledge bases don't inherently distinguish between a policy document updated yesterday and one that hasn't been reviewed in 18 months. Both are served with equal fluency and confidence. In high-change environments—pricing updates, regulatory compliance shifts, product modifications—agents acting on stale information create direct CX and compliance liability.
In traditional keyword search systems, agents see document dates and metadata, exercising some judgment about recency. With AI-synthesized answers, source metadata is often invisible—removing the friction that previously prompted verification.
Research indicates knowledge base coverage rates for frequently asked questions often hover around 10-12%, meaning the system cannot answer 88-90% of common queries. When combined with the fact that 30-40% of organisational knowledge resides in siloed systems AI cannot access, the risk of serving outdated or incomplete information multiplies.
Key factors that accelerate content staleness:
- No mandatory review cycles or automated expiry flags
- Content ownership not assigned to specific subject matter experts
- No visible recency metadata alongside AI-generated answers
- High rate of policy, product, or regulatory change
AI Hallucinations in the Enterprise KB Context
Enterprise AI knowledge bases face a failure mode distinct from general LLM hallucination. When drawing from multiple internal documents to synthesise a response, the system can produce answers that are coherent but factually wrong: combining elements from different policy versions, misattributing procedures, or filling gaps with plausible inference.
Research shows that even with retrieval-augmented generation (RAG), AI tools hallucinate approximately 17% of the time in legal knowledge contexts, while retrieval errors occur in 15-40% of queries in multi-agent RAG systems. The LLM accounts for only 10-20% of a RAG system's effectiveness; the remaining 80-90% is determined by upstream retrieval processes.
Downstream consequences in contact centres:
- Agents deliver incorrect refund policies, escalation procedures, or technical troubleshooting steps
- Errors are delivered with the same authoritative tone as correct answers
- Quality assurance teams struggle to identify hallucinations during spot checks
- Compliance-sensitive guidance in banking, healthcare, and insurance creates regulatory exposure
Research on automation bias reveals the severity: when presented with incorrect AI suggestions, cardiology fellows' diagnostic accuracy dropped from 84.86% to 41.66%. Even highly experienced professionals trust AI outputs that contradict their own judgment.

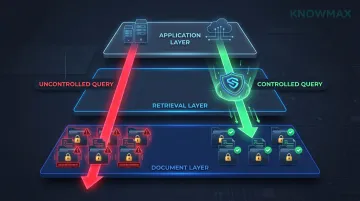
Permission Bleed: When AI Search Ignores Who Should See What
Semantic AI search—a core feature of modern AI knowledge bases—searches across content holistically to find the most relevant match. Without carefully architected role-based access controls, it can surface internal-only documents to users who were never meant to see them: escalation thresholds, pricing exceptions, sensitivity flags, agent-only notes.
This risk is particularly acute when the same AI knowledge base serves multiple user types: frontline agents, supervisors, customers via self-service, and partners. Each tier expects different information access, but AI systems don't inherently enforce those boundaries.
Forrester predicts that by 2028, 25% of enterprise security breaches will trace to AI agent abuse—not malicious intent, but search systems failing to enforce permissions before surfacing information. Vector search engines optimise for semantic similarity, not authorisation.
The OWASP Top 10 for LLM Applications (2025) identifies two directly relevant risks:
- LLM02: Sensitive Information Disclosure — LLMs inadvertently revealing confidential data or proprietary information
- LLM08: Vector and Embedding Weaknesses — RAG-specific risks including unauthorised access via vector database queries that bypass document-level permissions
Organisations deploying AI knowledge bases must audit RAG pipelines for access control enforcement at the retrieval layer, not just the application layer. Each new content source added to the knowledge base expands the attack surface if retrieval-layer permissions aren't enforced from the start.
The Governance Vacuum: Nobody Owns What the AI Writes
When AI author tools generate, rewrite, or summarise knowledge base content, the traditional chain of custody breaks. In conventional knowledge management, a subject matter expert writes an article, a reviewer approves it, and a named owner maintains it. When AI produces a rephrase or synthesis, that accountability dissolves.
The vacuum compounds over time: AI-authored content proliferates, review cycles are skipped because "the AI kept it current," and errors accumulate without a human expert catching them. In regulated industries—banking, insurance, healthcare, telecom—this creates direct compliance exposure, not just operational friction.
Regulatory frameworks are explicit:
- The UK Financial Conduct Authority states that "firms that use AI as part of their business operations remain responsible for ensuring compliance with our rules, including in relation to consumer protection"
- The US Consumer Financial Protection Bureau confirms that "financial institutions are responsible for the actions of their chatbots," with inaccurate information risking UDAAP violations
Purpose-built knowledge management platforms like Knowmax address this by building content ownership, review workflows, and audit trails directly into the authoring process. Even when AI assists with content creation, a named human owner must be assigned before publication, preserving accountability through a maker-checker approval process.
Institutional Knowledge Drain: The Silent Disappearing Act
When enterprises deploy AI knowledge bases, there's often an implicit assumption that experienced agents' knowledge is "already in the system." That assumption is rarely true. Institutional knowledge—the judgment calls, edge-case handling, escalation nuance, and product expertise that veteran agents carry—is rarely fully documented.
Approximately 90% of organisational knowledge exists in tacit, undocumented form, according to research on knowledge transfer. As AI takes over knowledge retrieval, the organisational incentive to capture that human expertise decreases.
What happens when knowledge capture stops:
- Agent turnover (averaging 40% annually in contact centres) erases undocumented expertise permanently
- New agents lack mentorship scaffolding because "the KB covers it"
- The system's quality plateaus or declines as product complexity grows but expert knowledge isn't captured
- Replacement costs reach up to $35,000 per agent, compounding the financial impact

The deskilling consequence is documented: a four-month study found that ChatGPT users exhibited 55% less neural connectivity compared to those working unassisted, and struggled to remember content they had co-authored moments prior.
How These Risks Play Out in CX and Agent Performance
The failure sequence is consistent: stale data produces wrong answers, hallucinations slip through because agents trust the system, and without governance, bad content spreads. The result is inconsistent resolution quality that's nearly impossible to trace — because the errors surface as agent mistakes, not knowledge base failures.
57% of customers will leave a brand after just one bad experience, according to Qualtrics research. Global businesses lose over $3 trillion annually due to service failures, with an average cost per lost customer of $243.
That customer attrition cost has a less visible counterpart inside the contact center. Agents conditioned to accept AI answers without verification gradually lose the reasoning skills needed for novel situations. When the knowledge base is unavailable, updated, or simply wrong, those agents can't improvise — and the operation loses resilience precisely when it needs it most.
The exposure is sharpest in regulated industries, where knowledge base errors carry legal and compliance consequences:
- The CFPB has documented consumer complaints about chatbot "doom loops," conflicting account information, and failures to recognize disputes
- Incorrect knowledge base-driven guidance can trigger regulatory scrutiny, customer complaints, and legal liability
- Gartner predicts that by 2030, GenAI cost per resolution will exceed $3, surpassing many offshore human agent costs — and this doesn't account for error remediation expenses
How to Build a Risk-Resilient AI Knowledge Base Strategy
The risks covered above share a common thread: they're all preventable with the right governance approach. Here's how to build an AI knowledge base strategy that holds up under enterprise pressure.
Enforce Knowledge Freshness as a System-Level Policy
- Establish mandatory content review cycles with automated expiry flags
- Assign named content owners to every article, including AI-generated content
- Configure the AI to display content recency metadata alongside answers
- Treat knowledge freshness as a performance metric, not an administrative task
Design Access Architecture Before AI Deployment, Not After
- Map user roles and permission levels explicitly across all user types (agents, supervisors, customers, partners)
- Test AI search behaviour across all roles before go-live to identify permission boundary violations
- Ensure semantic search is scoped to role-appropriate content pools
- Audit search outputs regularly for unintended information exposure
Maintain Human Knowledge Capture as a Parallel Practice
- Schedule structured knowledge elicitation sessions with subject matter experts and veteran agents
- Treat undocumented tribal knowledge as a strategic asset requiring active capture
- Create incentive structures that reward knowledge contribution, not just consumption
- Use structured authoring templates and guided workflows to reduce capture friction
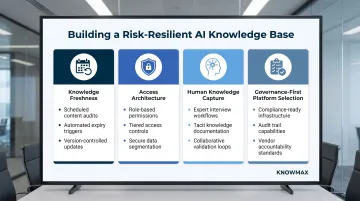
Choose Platforms Built for Enterprise Governance, Not Just AI Performance
When evaluating vendors, require evidence of:
- Role-based access controls with RAG-level enforcement
- Content ownership workflows with mandatory approval chains
- Audit logging for compliance verification
- Compliance certifications relevant to your industry
Platforms like Knowmax carry GDPR, SOC 2, ISO 27001, and HIPAA certifications precisely because governance was built into the architecture from the start. When evaluating any vendor, the critical question isn't how fast the AI answers — it's what happens when the AI answers incorrectly.
Frequently Asked Questions
Frequently Asked Questions
What are some business risks associated with AI?
Broad categories include data privacy breaches, algorithmic bias, security vulnerabilities, compliance failures, and workforce disruption. For AI knowledge bases specifically, the more immediate operational risks are stale content delivery, hallucinated answers, and governance gaps that erode answer quality over time.
What are the risks of AI in the workplace?
Employee over-reliance on AI outputs erodes critical reasoning skills, particularly when AI handles complex decisions without verification workflows. Compliance risks emerge when AI-generated content lacks human accountability, and automation bias causes professionals to trust incorrect AI suggestions over their own expertise.
Can AI knowledge bases give incorrect answers to customers?
Yes, through both hallucination (synthesizing plausible but wrong answers from multiple sources) and content staleness (serving accurate-looking outdated information). These failures are harder to detect than traditional knowledge base errors because they're delivered with natural-language confidence, with no visible signal that the answer may be wrong.
How do you prevent AI search from exposing restricted content in a knowledge base?
Build role-based access controls that scope AI search to permitted content at the retrieval layer — not just the application layer. Test this before deployment, then audit regularly to confirm semantic search isn't bypassing document-level permissions.
What is knowledge decay and why does it matter in AI systems?
Knowledge decay is the gradual degradation of information accuracy as policies, products, and procedures change while knowledge base content goes unreviewed. It's more dangerous in AI systems because stale content is served with the same confidence as current content — without the visual cues agents used in traditional search to flag uncertainty.
How can enterprises ensure their AI knowledge base stays accurate and compliant?
Start with governance infrastructure before optimising for deployment speed. Core requirements include:
- Mandatory review cycles tied to content expiry dates
- Named ownership for every article
- Audit trails tracking all changes
- Platform-level compliance certifications (GDPR, SOC 2, ISO 27001, HIPAA)


